Triplet V1
The First Foundation Model for Pathology Multi-scale Reasoning
Triplet V1 features cross-scale reasoning as its core capability, enabling the model to perform visual planning, step-by-step verification, and conclusion convergence like a pathologist, with traceable evidence chains.
Cross-scale Reasoning, Fully Explainable
Triplet features unique multi-scale explainable evidence chain training with stepwise evidence-based reasoning, enabling clinically auditable reasoning expressions.
Interactivity Reasoning, Explicit Traceable
Stepwise display from low-magnification tissue architecture to high-magnification cytological evidence; clinicians can modify and trace at any time, forming a closed-loop reasoning workflow.
Human-in-the-loop Data Flywheel
Human-in-the-loop data annotation: AI generation, clinician review, and feedback training build a data-to-AI capability flywheel for continuous improvement.
Why Multi-scale Reasoning
Pathology diagnosis is not about viewing a single image. It starts with low-mag global scanning, then mid-mag structural localization, and finally high-mag cytological confirmation. Triplet defines this cross-scale workflow as the core capability target and designs training and evaluation accordingly.
Global scan: Identify overall tissue architecture and abnormal region distribution as the starting point for multi-scale reasoning.

Low-power view shows disrupted duct/acinar structures with stromal fibrosis and cellular crowding, indicating tissue structural disruption; mid-power view shows disorganized epithelial cell arrangement, increased nuclear size and hyperchromasia, incomplete basal lamina and loss of myoepithelial cells, indicating epithelial atypia progression; high-power view shows significant nuclear atypia, increased nuclear-to-cytoplasmic ratio, uneven chromatin distribution and pathological mitotic figures, consistent with malignant tumor cell characteristics.
Disrupted duct/acinar structures with stromal fibrosis and cellular crowding.
.png&w=3840&q=75)
At 10× magnification, dysplastic duct/acinar structures show irregular arrangement with back-to-back patterns, significant increase in stromal proportion with sclerosing changes, dense nuclear clusters with varying sizes, mild stromal inflammatory infiltration, overall compact structure.
Disorganized epithelial cell arrangement, increased nuclear size and hyperchromasia, visible nucleoli, reduced cytoplasm, incomplete basal lamina with loss of myoepithelial cells.
.png&w=3840&q=75)
At 20× magnification, irregular tissue architecture, epithelial cells show in-situ proliferation in nests or strands, loss of cell polarity, increased nuclear size and hyperchromasia, visible nucleoli, reduced cytoplasm, stromal fibrosis with inflammatory cell infiltration, interrupted basal lamina, and loss of myoepithelial layer.
Significantly atypical nuclei with increased nuclear-to-cytoplasmic ratio, deep chromatin distribution, visible nucleoli, and pathological mitotic figures.
.png&w=3840&q=75)
At 40× magnification, irregular tissue architecture, dense cellular arrangement with loss of polarity, increased nuclear size and irregular shape, deep chromatin distribution, visible nucleoli, increased nuclear-to-cytoplasmic ratio, stromal fibrosis with inflammatory cell infiltration, multiple pathological mitotic figures.
What Triplet V1 Can Do
Cross-scale Reasoning and Evidence Linking
Explicitly connects evidence across at least two magnifications, avoiding single-scale guessing.
Multi-region Heterogeneity Understanding
Learns contextual relationships among multiple ROIs along a Path to understand diagnostic significance for the whole WSI.
Structured Output (Clinical Review Ready)
Outputs Reason and Caption at each magnification, forming cross-scale reasoning chains and summaries.
Bilingual Output
Supports Chinese and English expression, with the primary focus on cross-scale reasoning and evidence chain capabilities.
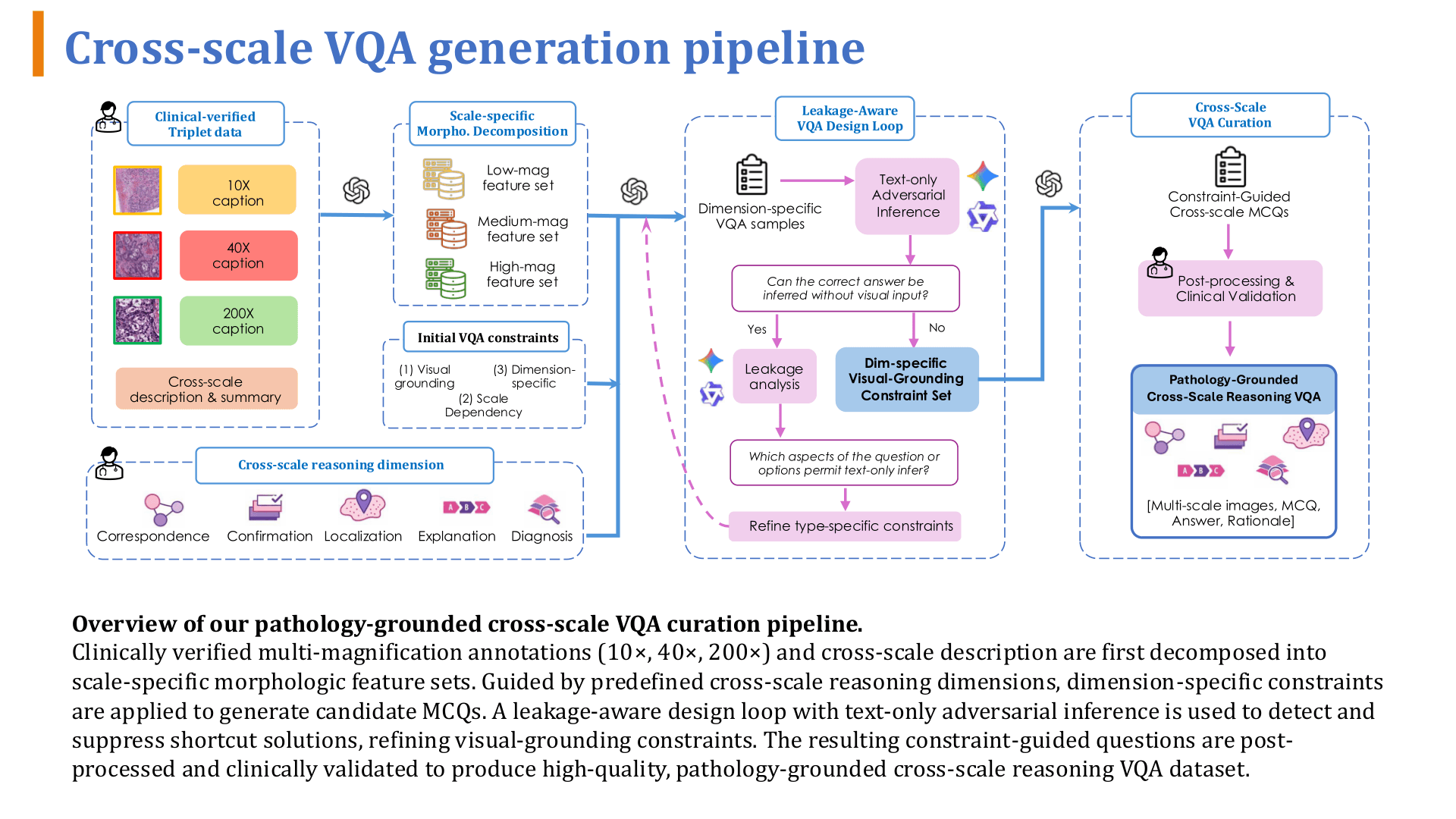
Core Mechanism: Triplet Structure
Triplet organizes learning with a triplet data structure: multi-scale images + selection rationale and pathological features + diagnostic significance and findings of the path. Each path is a complete cross-scale Path (10x → 40x → 200x).
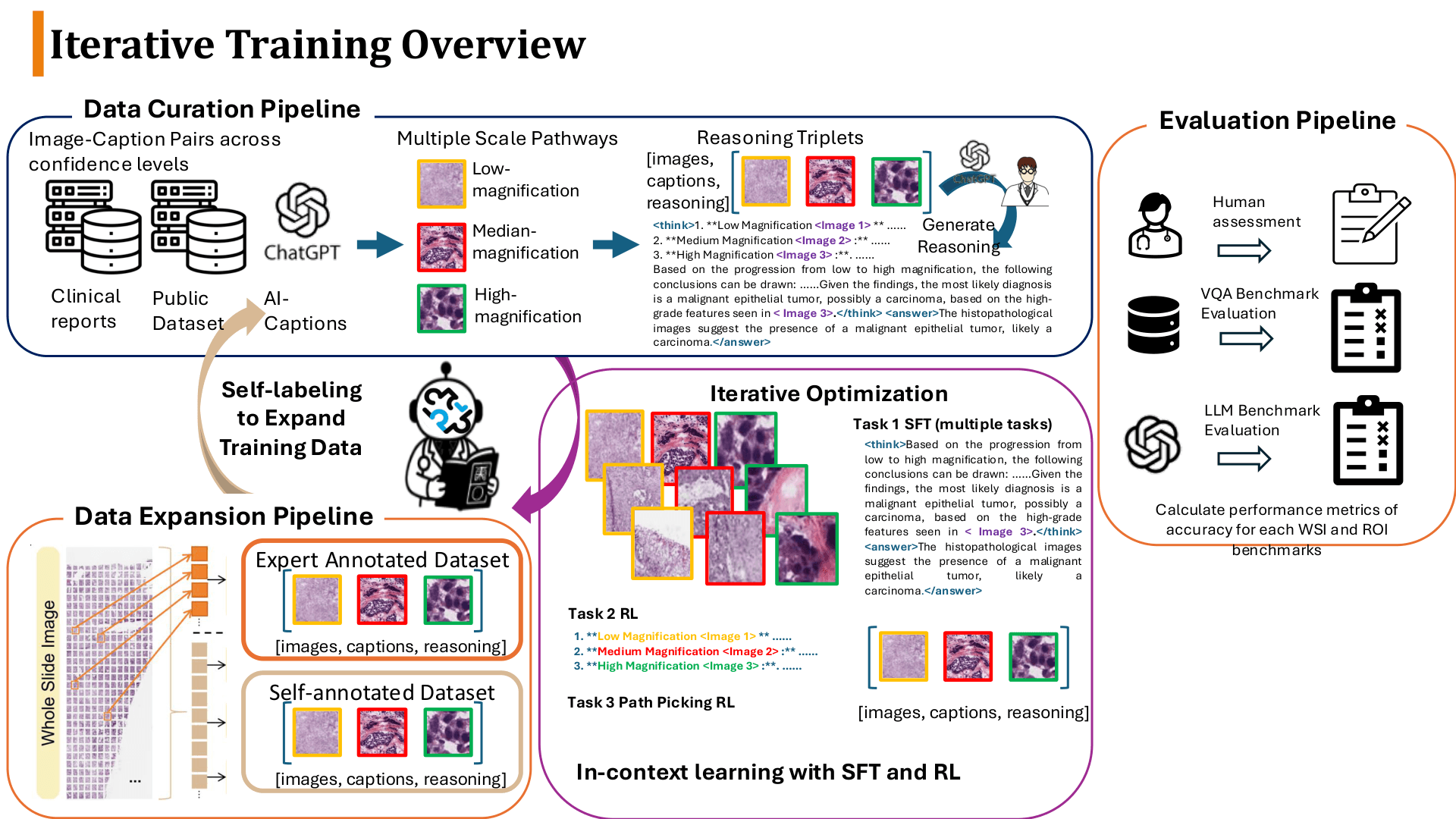
Data & Platform: From Annotation to Reasoning Data Pipeline
The Triplet data review platform addresses multi-center data distribution and modality diversity, building a high-quality, multi-scale, and explainable reasoning data system.
AI Generation Phase (Automated)
Global WSI analysis to generate an overview (low-mag structure, tissue distribution, heterogeneity).
Generate candidate Paths and build cross-scale Paths for each region (10x -> 40x -> 200x).
Generate Reason / Caption / reasoning chain / summary at each level.
Doctor Review Phase (Human-in-the-loop)
Correct unreasonable magnification motivations and inaccurate descriptions.
Revise cross-scale reasoning chain logic and final summaries.
After review approval, feed back into training for the next data iteration cycle.
Training & Evaluation
SFT teaches the model evidence pathways; RL makes "reasoning ability" reliably measurable.
SFT: Teaching Evidence Pathways
Cross-scale Paths (10x → 40x → 200x) are built for each region at multiple scales, learning Reason / Caption / reasoning chain / summary at each level, teaching the model "why to magnify, what is seen, and how to summarize".
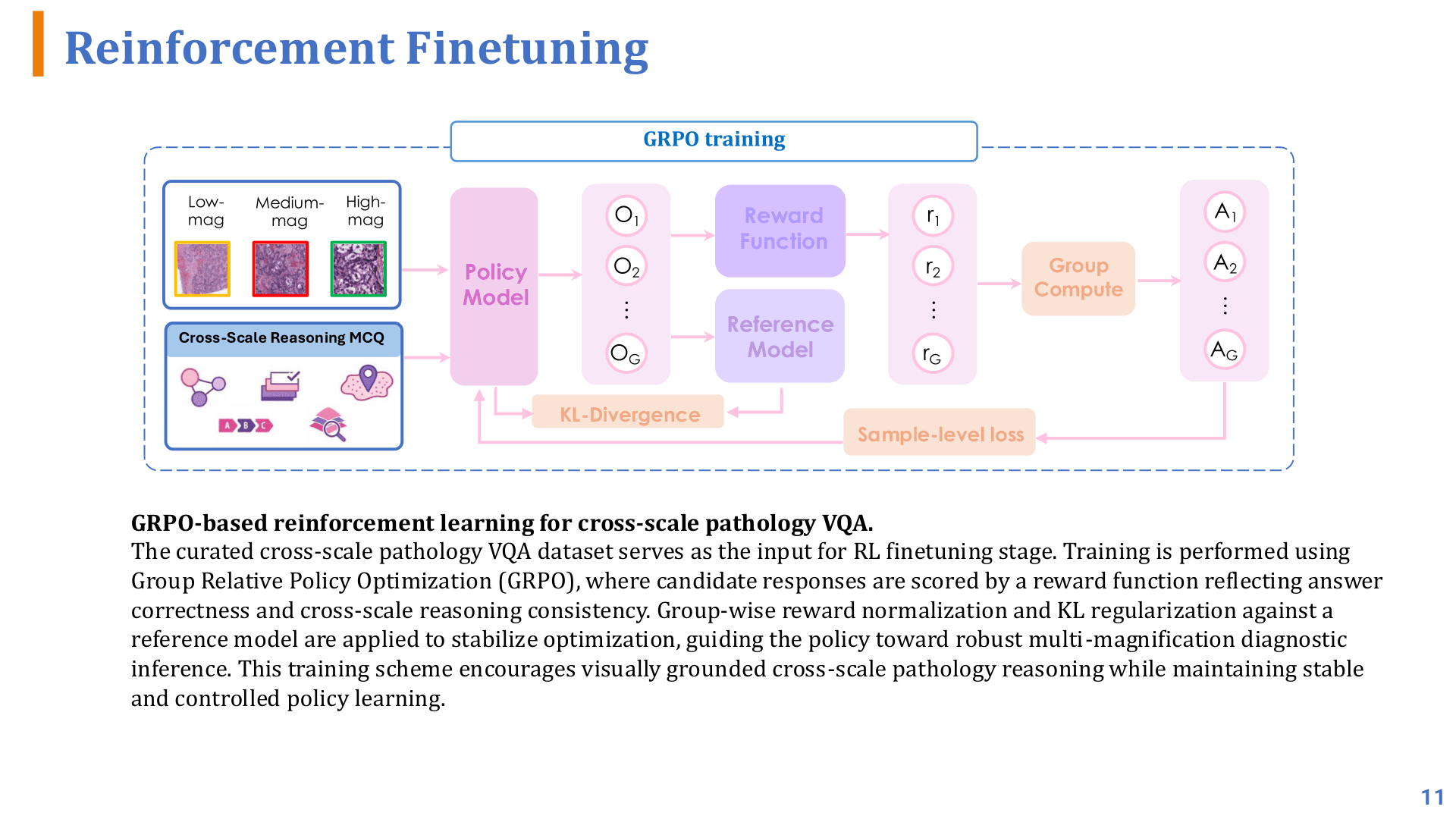
RL: Making Reasoning Reliably Measurable
A leakage-aware mechanism suppresses text shortcuts: text-only adversarial inference is performed first, and if the correct answer can be obtained without viewing the image, it is flagged as leakage and iteratively corrected. GRPO alignment then rewards answer correctness and cross-scale reasoning consistency while constraining output format stability.
Experimental Results
Triplet V1 achieves significant leading performance on two core evaluation tasks.
Accuracy on cross-scale multi-image TripletVQA-Test
Task: Accuracy on cross-scale multi-image TripletVQA-Test
| Domain | Model | Correspondence | Confirmation | Localization | Explanation | Diagnosis | Average |
|---|---|---|---|---|---|---|---|
| General | Qwen2.5VL-7B | 41.8 | 47.3 | 71.1 | 44.3 | 63.7 | 53.6 |
| Gemini 3 Flash | 48.3 | 58.7 | 71.6 | 53.7 | 72.1 | 60.8 | |
| GPT-5.2 | 47.8 | 59.7 | 74.1 | 45.8 | 65.2 | 58.5 | |
| Medical | LLaVA-Med-7B | 25.9 | 16.9 | 28.4 | 20.9 | 24.9 | 23.4 |
| HuatuoGPT-V-7B | 37.8 | 45.8 | 65.7 | 46.8 | 55.7 | 50.3 | |
| Lingshu-7B | 47.3 | 63.7 | 62.7 | 48.3 | 61.2 | 56.6 | |
| Pathology | Quilt-LLaVA | 32.3 | 14.4 | 45.3 | 30.3 | 29.4 | 30.3 |
| CLOVER | 37.3 | 61.7 | 73.1 | 46.3 | 65.7 | 56.8 | |
| Patho-R1 | 31.8 | 40.3 | 59.7 | 56.2 | 68.7 | 51.3 | |
| Triplet V1 | 80.6 | 89.1 | 84.6 | 76.1 | 84.1 | 82.9 |
Question
Based on the cellular morphology, which layer of stratified squamous epithelium is most prevalent on the left side of the image?
Model Response Comparison
Case data from the Triplet-V1 paper, showing response comparisons across models on cross-scale reasoning tasks.
Online Trial
Upload or select a sample image to experience Triplet cross-scale reasoning output.
Image Input
Upload or use preset images
Analysis Result
Product Offerings
Three forms for system integration, workflow collaboration, and research-grade reinforced reasoning.
Triplet API
Integrate cross-scale reasoning into your system: VQA, structured descriptions, evidence chain output, and QC interfaces.
Triplet Agents (Collaborative)
Workflow-oriented: region selection -> evidence aggregation -> report drafting -> human doctor supervision loop.
Triplet Reasoning Edition (Research/Advanced)
Built on leakage-aware data curation + GRPO reinforcement learning for improved cross-scale consistency and controllable output.
FAQ
What makes Triplet V1 fundamentally different?
Cross-scale reasoning is the primary capability. Training, data, and evaluation are all designed around closed-loop evidence chains, avoiding single-scale black-box judgments.
How do you ensure data reliability?
Iterative human-in-the-loop: AI generates first, then doctors review and correct, feeding back into training to continuously improve data quality and traceability.
Apply for Triplet V1 Partnership
If you want to validate cross-scale reasoning in real pathology scenarios, contact our team for early access, API integration, and Agents collaboration plans.